Why Sharding Gets Hard, and Why You Need Vitess
Once upon a time, there was a company called TubeYou. TubeYou was a video sharing platform which was expanding very rapidly. When they first started out they stored all their data on a single MySQL instance. All reads and writes went to this single instance, and they operated at a small enough scale that this was just fine for them. As the following diagram shows TubeYou’s database deployment looked very simple.

But TubeYou was growing very fast, and their single database deployment could not keep up with their traffic. So they decided they would introduce some replicas to service read traffic. That way reads could be spread out across multiple nodes but all writes could still be handled out of a single node. So TubeYou updated their database deployment to look as follows

Now this certainly helped TubeYou scale out their reads but it did not help with scaling out their writes. Additionally they saw that their total volume was getting so big it was becoming hard to pay for a machine large enough to hold all their data on a single instance. Due to these two problems TubeYou decided they needed to split their database into physically separate databases each of which would own a section of the keyspace. Or in other words TubeYou decided they needed to shard their database.

Through sharding TubeYou managed to solve two problems
- Their total data volume was no longer limited to what could fit on a single host.
- They were able to get write throughput beyond what they could get on a single host.
But TubeYou paid several costs for these gains.
- The applications at TubeYou had to start understanding which shard to route their queries to. Baking in this logic to each application was a pain.
- It took TubeYou a long time and a lot of developers to figure out how to migrate their single node database to a sharded database without taking downtime. This was a very expensive migration that they really did not want to do again.
- TubeYou had to start dealing with a whole cluster of database nodes rather than just one. This meant that failures started happening at a higher frequency and the oncall would would have to wake up often in the middle of the night to figure out how to repair nodes which had failed.
But the problems with sharding got even harder for TubeYou. TubeYou was growing so fast that they started to expand globally and clients were connecting to their databases from all over the world. Additionally TubeYou started to become very nervous about having all their databases located in a single region. Therefore management decided that the data had to be spread across multiple regions. And this resulted in a database cluster that looked as follows:
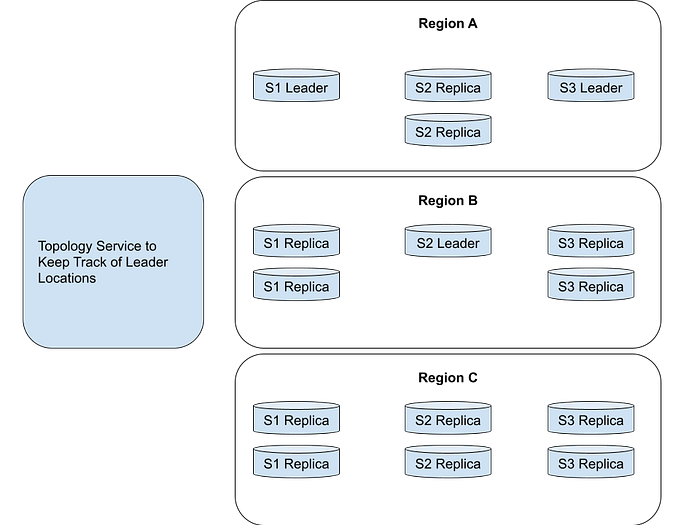
At this point the list of problems TubeYou had to deal with in managing this cluster were a bit overwhelming:
- There were so many database nodes that nodes where failing all the time. These failures had to detected and new nodes needed to be brought into the cluster. These new nodes had to catch their state up to match the existing nodes in the cluster.
- When the master would fail a failover would need to be triggered.
- Schema rollouts across all shards in all regions where very complex.
- A topology service had to be introduced to keep track of leader location and route user queries to the correct locations.
But even beyond these problems the real kicker was TubeYou realized that if they ever had to reshard their database, now that it had reached this level of complexity, they were in for a world of hurt.
The TubeYou story illustrates a common progression of database deployments a company will go through and illustrates the increasing amount of pain the company will experience at each step.
YouTube was facing these problems which prompted them to build Vitess. Vitess is a solution to operate large scale MySQL clusters. It takes care of much of the complexity that was illustrated in the TubeYou story. In the posts which follow I will cover the following:
- The features Vitess offers
- Its high level architecture
- How query routing works
- How reads and writes serviced
- How failures handled
- What we can learn from Vitess
If you want to checkout the next post in this series you can find it here.
