An Overview of Cadence
What problem does it solve?
Let’s imagine you want to build Uber Eats. There are fundamentally two separate concerns you are going to have to address
- How do you write the actual business logic? (e.g. how do you charge a credit card, how do you notify a driver, how do you figure out which driver to dispatch)
- How do you orchestrate that logic to run reliably in an environment in which dependencies can fail?
It is important to observe that while these concerns can be coupled together, they are logically distinct concerns. It is also important to note that getting the second concern right is hard, lets look at a few examples that demonstrate this
- Let’s say your business logic needs to call service
Foo. So you write some code to call serviceFooand run it on some machine. Now let’s say that machine dies beforeFoois actually called. What do you do now? You need to have some other machine take over. This means you need a method to determine that the first machine died, and a method to rebalance the work that machine was doing to a new machine. - Let’s say you want to wait for an hour before running a piece of business logic. If you just include a
time.Sleep(time.Hour)this is going to break if the machine you are running on restarts. So again you need a method to durably persist this idea of sleeping and you need a method to periodically check when it’s time to wake up. - Let’s say you need to write to a database and write to a durable log. AND let’s say you need both of these to happen together. What happens if you write to the database and the machine you are running on dies before you write to the log? Again you need some method to detect this failure, figure out where you left off, and preform the next action that you have not yet done.
Solving problems like this are doable. Typically these problems are solved by some combination of the following tools
- Durable queues with a pool of workers polling off items from the queue and processing them.
- Durable cron services which can give callbacks at some regular interval.
- Database TTLs on rows to do some automatic cleanup of left over state.
- Fence tokens in order to do deduplication of calls to thereby get idempotency.
- Using some method to determine membership, and using heartbeating to detect liveness.
While these methods do indeed enable building the type of long running applications we have been talking about, using these tools together correctly is hard. Importantly getting this orchestration right has absolutely nothing to do with the actual business logic you care about.
Cadence provides a set of primitives which make doing this type of orchestration much easier. Think of Cadence as a developer friendly SDK + managed service which abstracts away the common problems of micro-service orchestration. You write your business logic and Cadence handles the orchestration. More specifically Cadence handles things like the following
- Failure detection
- Doing retries
- Task queuing and processing
- Durable timers
- Heartbeating for liveness detection
- Recording execution progress
- Handling timeouts
How do users interact with Cadence?
Users of Cadence write a workflow using the Cadence client SDK. This workflow contains two types of code.
- Workflow Code: Workflow code is a representation of the orchestration steps that need to be preformed. The key feature of workflow code is it can be run an arbitrary number of times without producing any side effects, and always runs the exact same way. Another mental model to think about workflow code is it is a deterministic state machine. Such that some set of inputs (state transitions) are provided and the code applies those inputs to the workflow definition to reach a deterministic state.
- Activity Code: Activity code is arbitrary code. It can do whatever the user wants it do it.
The user of Cadence writes their workflow definition code and their activity code using the Cadence client SDK. The SDK is a fat client that does three things
- Provides a framework for users to define their workflows against.
- Owns the responsibility to actually execute user defined code.
- Makes calls to the Cadence server to record user workflow progress.
So when users are defining their workflows they do not actually need to directly make calls to the Cadence server. They simply define their workflow using the Cadence client SDK and the fat client takes care of the rest.
In order to make this a little more clear let’s look at a sample workflow definition.
package helloworld
func init() {
workflow.Register(Workflow)
activity.Register(helloworldActivity)
}
func Workflow(ctx workflow.Context, name string) error {
ao := workflow.ActivityOptions{
ScheduleToStartTimeout: time.Minute,
StartToCloseTimeout: time.Minute,
HeartbeatTimeout: time.Second * 20,
}
ctx = workflow.WithActivityOptions(ctx, ao)
logger := workflow.GetLogger(ctx)
logger.Info("helloworld workflow started")
var helloworldResult string
err := workflow.ExecuteActivity(ctx, helloworldActivity, name).Get(ctx, &helloworldResult)
if err != nil {
logger.Error("Activity failed.", zap.Error(err))
return err
}
logger.Info("Workflow completed.", zap.String("Result", helloworldResult))
return nil
}
func helloworldActivity(ctx context.Context, name string) (string, error) {
logger := activity.GetLogger(ctx)
logger.Info("helloworld activity started")
return "Hello " + name + "!", nil
}Here we can see the user is using the Cadence client to do the following
- Register a workflow definition and an activity definition.
- Define the workflow logic.
- Define the activity logic.
- Inside the workflow logic one of the steps in the orchestration is to run the activity.
At this point it should be clear what problem Cadence solves and how users interact with Cadence. The next section will explain how Cadence is built.
How is it built?
What does the lifecycle of a workflow look like?
In order to understand how Cadence is built, it is useful to understand what Cadence does to manage a workflow from workflow from start to finish. So let’s tell a little story about Bob writing a workflow to build Uber Eats and run an instance of that workflow.
- Bob decides he wants to use Cadence to build Uber Eats. He goes ahead and writes his workflow definition and activities using the Cadence client SDK.
- Bob goes ahead and deploys this code to a pool of nodes that he is responsible for owning. These nodes will include the Cadence client. As part of the Cadence client there will be a workflow poller and an activity poller. Both of these pollers are issuing long polls against the Cadence server to get new events that need to be applied to the workflow. The workflow poller is polling for tasks which will advance the point of execution in workflow definition and the activity poller is polling for tasks which will result in an activity being run. So when Bob deploys his code there are a bunch of machines which contain Bob’s workflow/activity definitions and the same machines are polling the Cadence server for updates to the workflow.
- Now at this point there is no actual workflow running. All that has happened so far is Bob wrote his workflow and activity definitions and deployed it. In order to get a running instance of the workflow Bob must say “Hey Cadence I want to start an instance running of my Uber Eats workflow.” Note that Bob can tell Cadence to do this an arbitrary number of times. So for a single workflow definition Bob could have million of instances of the workflow running. Lets just say in this case there is some RPC endpoint that is called when a new Uber Eats order is placed. In this example what would happen when that RPC endpoint is called is Bob would make an RPC call to the Cadence server to say “Start my workflow.” In order to start a workflow the customer must provide a
workflowIDas well as the function signature of the workflow definition. TheworkflowIDuniquely identifies a single running instance of a workflow. Let’s just say theworkflowIDthat Bob decided to use to identify this running workflow instance isfoo123(in a real world application theworkflowIDwould probably have been a uuid that identified the Uber Eats trip). - The Cadence server receives this start request and it creates two entities in the database. The first is some metadata about the workflow and the second is a log of execution for that workflow. The log of execution is an append only log which will record every step the workflow ever takes. Internally this log is referred to as
workflow history.Theworkflow historyis the most key piece of Cadence as we will see later. - Once Cadence has persisted this metadata and an empty
workflow historyCadence will respond back to Bob saying “Hey Bob I successfully started your workflow.” Note that at this point none of Bob’s actual workflow code has been run yet — but Cadence guarantees that it will be run. It does this by creating something called aDecisionTask.ADecisionTaskis a nudge sent from the Cadence server to Bob’s worker hosts indicating that there is some new stuff that needs to be run against Bob’s workflow definition. So when Cadence creates one of theseDecisionTasksone of Bob’s workflow pollers will unblock, fetch theworkflow historyfrom Cadence and run that history against Bob’s workflow definition. Remember when I said that the workflow code has to be deterministic and not produce side effects? Well this is why… Cadence will send the full history of the workflow execution to Bob’s workflow workers and the client will run that history against Bob’s workflow definition (this can happen an arbitrary number of times during the lifecycle of a workflow). This will bring the workflow code to a deterministic point in its execution. The Cadence client is responsible for running the history against the workflow logic and as it does this it collects a set of logical next steps that the workflow wants to take. For example let’s say the first line of the workflow definition is to wait for one hour. In this case the Cadence client would apply an empty history against the workflow definition, encounter this sleep statement, and make a request to the Cadence server indicating that the next step in the workflow is to wait for one hour. The mental model here is very important to understand —workflow historyis provided as input to the workflow definition and the workflow definition produces a set of next steps that the workflow will take. The model isworkflow historyas input and next steps as output. This whole flow is owned by the Cadence client — the user does not have to handle any of this — they simply write their workflow and activity logics. - So at this point Cadence has created the first
DecisionTaskthat unblocked a workflow worker, ran the first part of the workflow, collected a batch of next steps and the Cadence client sent those next steps to the Cadence server to record. The Cadence server records those next steps to the workflow history and does whatever it needs to do to manage those tasks. For example in the case of the user wanting to wait an hour, the Cadence server would be responsible for creating a durable timer that will wait an hour. When this timer fires it means there are new events for the workflow (i.e. the workflow will be able to make some forward progress). So Cadence creates a newDecisionTaskand the process repeats itself — Cadence ships the updatedworkflow historyto the poller, the Cadence clients applies that history (this time the timer will have already fired), this time the workflow reaches a point further than it reached last time, a new batch of next steps is collected and sent back to the Cadence server. - At this point you might be asking how do activities fit into all of this. So far all we have talked about is the workflow making progress via
DecisionTasks.Well you can think of activities as simply another type of next step in the workflow. The workflow can say it wants to run activityFoowhen it does this the Cadence client will report that as a next step to take in the workflow, the Cadence server will create some activity task which will result in some activity poller being unblocked and then the activity will run. So in this sense activities are nothing special they are just some black box from the perspective of the workflow that takes some input and produces some output in order to enable the workflow to advance. It is important to note that the machines that run workflow code are not necessarily the same machines that run the activity code. The mental model is there are just a collection of pollers which are constantly asking the Cadence server to give them a nudge to either run some activity or make some progress in the workflow. It’s possible, and likely, that machine X tells Cadence to run some activity but that activity is actually run on machine Y. From this perspective there is no single machine running the workflow, instead the log of execution is stored in Cadence and there is simply a collection of hosts which contain the code Cadence needs to run in order to advance the workflow to the next state. - This process of
workflow historyin, next steps out continues until the workflow reaches the end. When that happens the client tells the Cadence server that the workflow has finished and the Cadence server closes theworkflow historyby appending some event saying “hey this workflow is at its end.”
And that is the story of how Bob ran instance Foo123 of the Uber Eats workflow from start to finish. Now that we understand how Cadence manages the lifecycle of a single workflow, let’s take a deeper dive into what the internals of the Cadence server look like.
What is the high level architecture of Cadence?
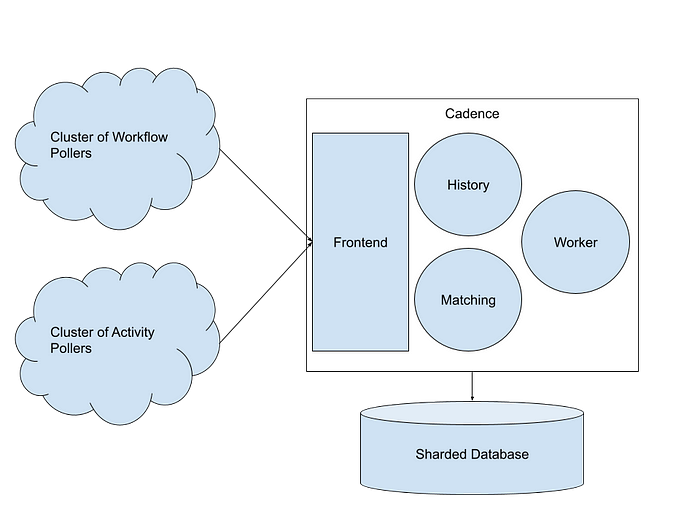
Cluster of Workflow Pollers: Collection of hosts managed by Cadence customer, which constantly issue long polls against the Cadence server to get notifications of when there are updates to apply to the workflow.
Cluster of Activity Pollers: Collection of hosts managed by Cadence customer, which constantly issue long polls against the Cadence server to get notifications when there are activities to run.
Frontend: A cluster of stateless nodes that handle all the types of tasks you would expect a frontend to handle: AuthN/AuthZ, rate limiting, request validation, etc… The frontend also serves as the routing layer by forwarding requests to the correct history/matching hosts.
History: A cluster of nodes organized into a consistent hash ring. Workflows are sharded onto this ring by workflowID. So a single shard contains many workflows, and a single host owns many shards. If a history host dies a gossip based protocol will be used to rebalance the shards to other nodes, those new nodes will load state from the database for the workflows they now own, and those nodes will start managing updates to the workflows. There is no durable state stored in the history nodes (that all belongs to the persistence layer) however the history nodes are stateful in the sense that certain workflows belong to certain history nodes.
Matching: A cluster of nodes organized into a consistent hash ring. The entities sharded onto the ring are called task lists. Task lists are basically just queues of tasks that workers are polling from. The details here are not that important — what is important to understand is matching is the component which owns the actual dispatching of workflow/activity tasks to the customer’s pollers. So when a long poll arrives at Cadence frontend, that call will be routed to the owning matching host which will manage the long poll and unblock it when a task becomes available for dispatch.
Worker: This is a collection of stateless nodes that preform background processing on behalf of the Cadence server. Examples of this include
- Archiving old workflow histories
- Replicating workflow state from one region to another
- Scanning the database to detect inconsistencies
Sharded Database: Cadence is built to be able to run on top of different types of databases. Fundamentally the only thing Cadence needs from a database is the ability to support consistency between entities. In the NoSQL world this is done with conditional updates, and in the SQL world this is done with row level locking and transactions. In theory the database does not have to be sharded but you will quickly run into scaling problems if you cannot scale out the persistence layer. Additionally note that since matching and history components both use sharding, the Cadence data model fits nicely into using a sharded database.
What are the main components of the history service?
It should be apparent at this point that the history component of Cadence is where the real magic happens. As we have learnt Cadence fundamentally manages append only logs of workflows’ executions. Ensuring the correctness of that log and adding to it is owned by the history component.
The history component in Cadence is too complex to dive into all the details of it, however it’s worth understanding at a high level what it is doing. Basically the history component preforms the following steps
- Receives a batch of next steps from the customer’s workflow.
- Creates a database transaction which will update the workflow history AND as part of the same transaction creates tasks in the database (more on these tasks in following steps).
- The tasks Cadence writes to the database are tasks that when processed will result in some update being dispatched to the customer’s workflow pollers or activity pollers. As a simple example, imagine the user set a timer for one hour. Cadence would create what is called a timer task in the database. The task processing component in Cadence would load that task from the database when its time to fire the timer, and then would (though matching component) notify the customer’s workflow that the timer has fired and the next steps of the workflow can be run.
So if we really zoom out what history component is doing is writing updates to the workflow, creating tasks, processing those tasks and dispatching notifications to the workflow that some progress was made.
What else is part of Cadence?
Believe it or not, despite all the complexity was have already gone over — everything we have covered so far is just the barebones core engine of Cadence. There are tons of things built around this core engine. In this section I will just give a super fast overview of some of the other things that exist as part of Cadence.
- Cross Region Replication: Cadence automatically handles replicating workflow state to remote regions. This enables failing over from one region to another without losing workflow progress.
- Archival: Old workflow histories are automatically archived into long term blob storage for later debugging and compliance.
- Cron DLS: Sometimes managing a pool of workers is overkill and really all the customer needs is a simple cron. In order to handle this Cadence built a DSL on top of Cadence that can be used to express simple cron jobs.
- Visibility APIs: Cadence provides a rich feature set to query workflows by secondary indices. For example customers can make queries like, “Give me the workflowIDs for all of my workflows that started after time X and ended before time Y and filter out those workflows to only include workflows that failed.” These APIs are powered by ElasticSearch and are super fast, given the huge amount of records they are processing.
- Query: Cadence supports the ability to register query handlers on workflows and call those query handlers just like you would call an RPC endpoint on some service. This enables building request/response like applications on top of a workflow.
Cadence offers much more than this feature wise. And within Cadence there are some pretty awesome optimizations, but I won’t spend too much time diving into all of these — just know that we have only scrapped the surface of Cadence’s internals and feature sets.
What can we learn from it?
In order to close I want to take some time to reflect on the higher level learnings we can take from Cadence.
From a technical perspective what did Cadence do well?
Value of Fat Client: The Cadence client SDK, as we have talked about, is very fat. It does caching, it provides a workflow execution environment, it abstracts away communication with the Cadence server and more. This fat client was totally necessary for Cadence. The reason the client being fat was a good thing is because the client-server interaction model for Cadence is super non-trivial. It would be unreasonable to expect the customer to get this interaction model correct. By having a fat client that complexity can be abstracted away. Additionally the fat client is needed to cache workflow state. If the client were a lightweight wrapper that just called into the Cadence server workflow state would have to be completely recreated every time there was an update — but by virtue of having a fat client the client can actually cache state and create a session with the Cadence server. This is a critical optimization within Cadence that is only possible by virtue of the client being fat.
Server Separation of Concerns: Cadence did a good job with the high level structuring of the server. As we discussed — it is broken up into four components which can be deployed and scaled separately. These four components each own a well defined set of responsibilities. The value of this separation is really two fold: (1) Separation of concerns helps manage complexity (2) Actually separating out different roles such that they can be deployed separately enables more fine grained scaling and service monitoring.
Start with Rock Solid Core: Cadence started by building a rock solid core engine. This core engine was composed of a few well defined building blocks. This core engine alone produced customer value. It also provided a foundation upon which more features could be added.
What are the weakness of Cadence?
Fixed Number of Shards: When a Cadence cluster is first provisioned, it is provisioned with a fixed number of shards. There is no way to update this number later without doing a complex database migration and taking downtime. This presents a problem because setting the original number of shards is a non-trivial problem. If the number is too low then the system will run into scaling bottlenecks. But if the number is too large then per shard overhead will significantly increase the cost of the system on the whole. I have seen that databases can split the shard space resulting in a doubling of the number of shards. It seems like something like this should be possible for Cadence.
Large Blob Sizes: When customers write their workflows they are subject to limitations around sizes of data they pass around. There are lots of limitations around blob sizes, and its not worth getting into the details, but just know that when customers write their workflow they have to be thoughtful of the size of data they pass around. In many cases this can make writing a Cadence workflow more awkward than writing “normal” code.
Customer Backwards Compatibility: Just like databases have backwards compatibility issues when a new schema is rolled out, Cadence customers also have to think about backwards compatibility when they rollout a new code definition for their workflow. As we know Cadence keeps track of the history of workflow execution. If new code is rolled out when there are running workflows in progress, it’s possible that those existing workflow histories cannot be applied to the new workflow code. This forces customers to do version checks which can get complex.
What non-technical things did Cadence do well?
Manage Velocity vs Debt Tradeoff: There is always a tradeoff between how fast a project is being developed and how much tech debt accumulates. A project with no tech debt is a poorly led project AND a project with so much tech debt its hard to implement anything new is also poorly led. There are lots of factors that go into deciding how to tradeoff velocity against tech debt. Features like the maturity of the project, the area of the trade off and the risk of the change are all considerations. Throughout the lifecycle of developing Cadence a good balance has been struck between these considerations.
Developer Friendly: Something Cadence really got right is putting the developer experience first. The Cadence team obsessed over making the client SDK abstractions clear and flexible. Something Cadence did a really good job of was not just blindly listening to single customers and implementing features based upon that single customer’s feedback, but instead trying to understand holistically the problems that were being faced by Cadence customers and designing clear abstractions to address those problems.
Easy to Start Small: One of the key attributes of Cadence that enabled it to spread so rapidly was the fact that it was very easy to start with a small use case and expand from there. Cadence has seen over and over that teams will test Cadence in some limited capacity and then once they discover its power they will use it in larger and larger ways. Cadence is very different from a database product in this way. Introducing a new database to an existing project requires a data migration. This is a huge effort and typically is treated as a one way door. Cadence is totally different than this — customers can try to use Cadence in some small part of their system and if it goes well they can consume it in more and more places.
I hope you enjoyed this overview of Cadence and that you learnt something valuable.
